最近 #archlinux-cn 又流行玩 teeworlds 了,然而我却连不上那个服务器。
情况很奇怪。我能 ping 通服务器 IP,TCP 连接也正常,UDP traceroute 也表现得很正常(对关闭端口能够完成,对开放端口会在最后一跳开始得到一堆星号),并且我连接的时候,服务器能看到我在连接。也就是说,TCP 和 ICMP 都正常,UDP 上行正常,下行出了状况。
难道是有防火墙?首先呢,我能连接其它服务器,说明我这边没有问题;大部分人能连接上服务器,说明服务器那边也没有问题。所以,问题出在路上。也确实有另外的北京联通用户连不上这个服务器。但是很奇怪啊,为什么单单只是这一个 IP 的 UDP 包丢失了呢?
于是继续试验。从最简单的开始,用 netcat / socat 尝试通讯。方向反过来,我监听,服务器那边连接。端口是我在路由器上做过端口映射的。结果是正常的。再来,服务器那边监听,我往那边发,果然我就收不到包了。按理说,UDP 双方是对等的,不应该换了个方向就出问题呀。难道是因为端口映射?Wireshark 抓包看到本地使用的端口号之后,在路由器上映射一下,果然就通了!
然后,我注意到了一件十分诡异的事情:虽然我和服务器能够通讯了,但是我的 Wireshark 上只显示了我发出去的包,却看不到回来的包!我抓包时按服务器 IP 做了过滤,所以,回来的包的源 IP 不是服务器的地址!
重新抓包一看,果然。服务器 IP 是 202.118.17.142,但是回来的包的源 IP 变成了 121.22.88.41……看起来这是联通的设备,在下行 traceroute 时能够看到有节点与它 IP 相似(121.22.88.1)。原来又是这著名的「联不通」又干坏事了 -_-|||
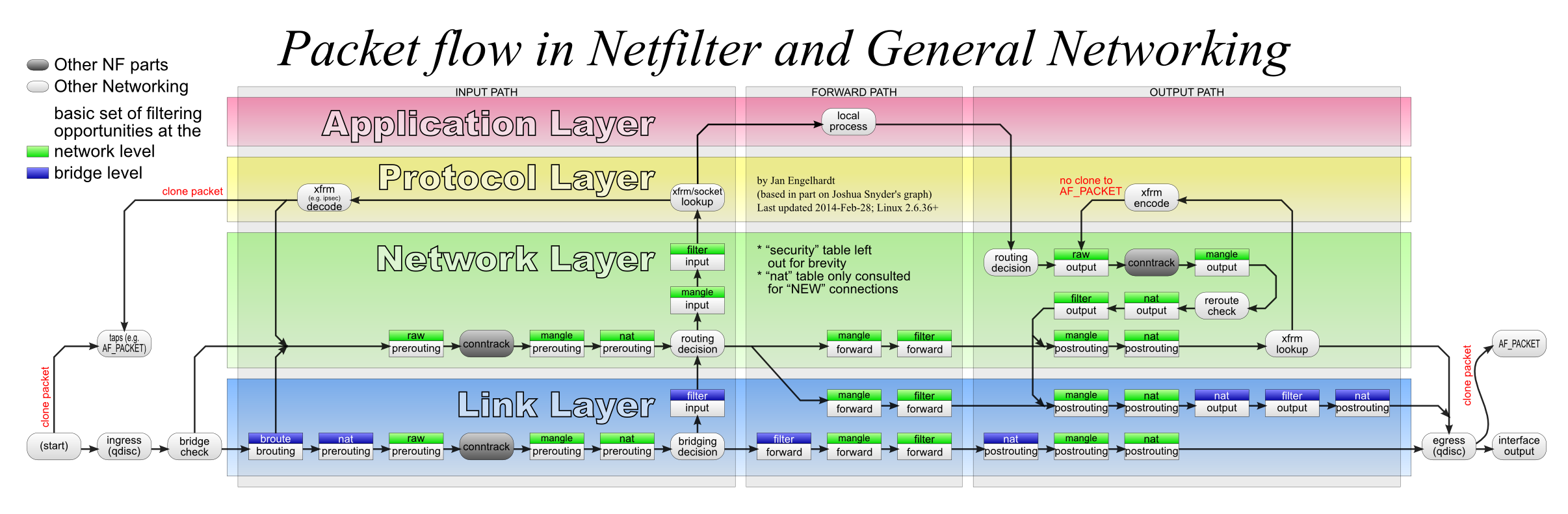
虽然 socat 接收 UDP 时不介意源 IP 变化了,但是 teeworlds 介意啊。并且 NAT 那边也会不知所措。所以,首先得告诉路由器把来自这个 IP 的 UDP 包全部扔给我:
ssh 192.168.1.1 iptables -I FORWARD -i ppp0.2 -p udp -s 121.22.88.41 -j ACCEPT
于是数据包有了。接下来是修正源 IP。我试过 SNAT,无效。这东西似乎只对本地发出的包有用?于是我又用 netfilter_queue 了。这东西很强大呢~一个简单的 Python 脚本搞定:
#!/usr/bin/env python3
from netfilterqueue import NetfilterQueue
from scapy.all import *
def main(pkt):
p = IP(pkt.get_payload())
# print('recv', p)
p.src = '202.118.17.142'
p.chksum = None
p[UDP].chksum = None
pkt.set_payload(bytes(p))
# print('fixed to', p)
print('.', flush=True, end='')
pkt.accept()
conf.color_theme = DefaultTheme()
nfqueue = NetfilterQueue()
nfqueue.bind(1, main)
try:
nfqueue.run()
except KeyboardInterrupt:
pass
然后是 iptables 命令:
sudo iptables -I INPUT -s 121.22.88.41 -p udp -j NFQUEUE --queue-num 1 --queue-bypass
scapy 这个神奇的网络库在 Arch 官方源里叫「scapy3k」。Python 的 netfilterqueue 模块需要用我自己修改过的这个版本。
2017年7月30日更新:Python 的依赖有点麻烦,所以我又写了个 Rust 版本,放在 GitHub 上了。


{kind=link}