咱买了一个录音笔,效果比使用笔记本话筒录音好多了还省电。当然啦,我也曾试过使用手机录音,结果是,没能录多久就中断了(Android 就是这么不靠谱)。
我的录音需要记录较为准确的时间信息。录音笔怎么知道现在是什么时间呢?还好它没有跟风,用不着联网!
它带了一个小程序,叫「录音笔专用时间同步工具」(英文叫「SetUDiskTime」,可以搜到的)。是一个 EXE 文件,以及一个 DLL 文件。功能很棒,没有广告,没有推荐,也不需要注册什么乱七八糟的账户,甚至都不需要打开浏览器访问人家官网。就弹一个框,显示当前时间,确定一下就设置好时间了。这年头,这么单纯的 Windows 软件还真是难得呢。
然而,它不支持我用的 Linux 啊。虽然我努力地保证这录音笔一直有电,但是时间还是丢失了几次,它的FAT文件系统也脏了几次。每次我都得开 WinXP 虚拟机来设置时间,好麻烦。
Wine 是不行的,硬件相关的东西基本上没戏。拿 Procmon 跟踪了一下,也没什么复杂的操作,主要部分就几个 DeviceIoControl 调用,但是看不到调用参数。试了试 IDA,基本看不懂……不过倒是能知道,它通过 IOCTL_SCSI_PASSTHROUGH 直接给设备发送了 SCSI 命令。
既然跟踪不到,试试抓 USB 的包好了。本来想用 Wireshark 的,但是 WinXP 版的 Wireshark 看来不支持。又尝试了设备分配给 VBox 然后在 Linux 上抓包,结果 permission denied……我是 root 啊都被 deny 了……
那么,还是在 Windows 上抓包吧。有一个软件叫 USBPcap,下载安装最新版,结果遇到 bug。那试试旧版本吧。官网没给出旧版本的下载地址,不过看到下载链接带上了版本号,这就好办了。去 commit log 里找到旧的版本号替换进去,https://dl.bintray.com/desowin/USBPcap/USBPcapSetup-1.0.0.7.exe,就好了~
抓好包,取到 Linux 下扔给 Wireshark 解读。挺小的呢,不到50个包,大部分还都是重复的。很快就定位到关键位置了:
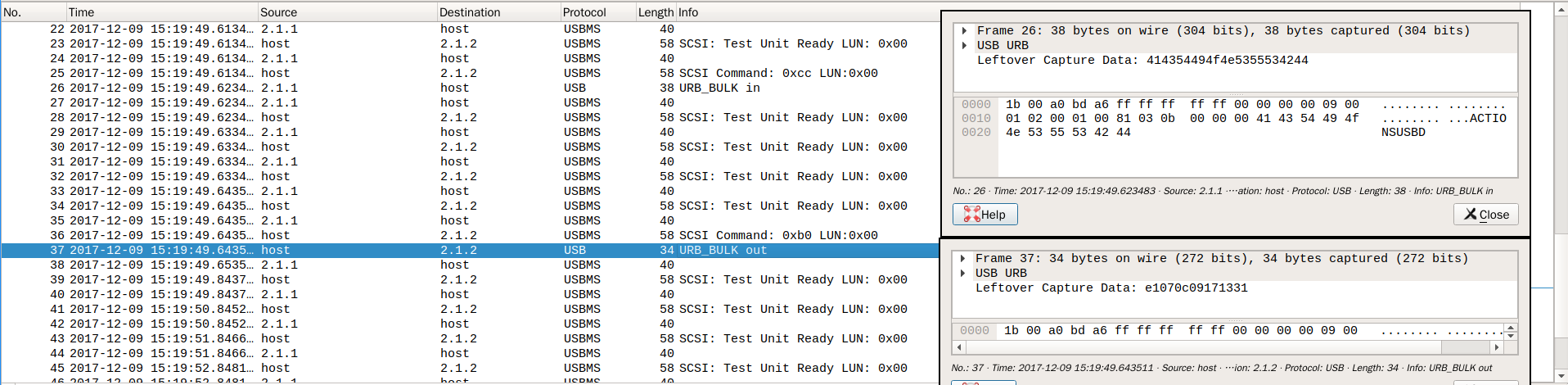
一个 0xcc 命令发过去,设备回复「ACTIONSUSBD」,大概是让设备做好准备。然后一个 0xb0 命令,带上7字节数据发过去,时间就设置好了。简单明了,不像那些小米空气净化器之类的所谓「物联网」,通讯加密起来不让人好好使用。
那么,这7字节是怎么传递时间数据的呢?我首先检查了UNIX时间戳,对不上。后来发送这个字串看上去挺像YYYYMMDDHHMMSS格式的,只是明显不是当时的时间。啊,它是十六进制的嘛!心算了几个,符合!再拿出我的 Python 牌计算器,确定年份是小端序的16位整数。
好了,协议细节都弄清楚了,接下来是实现。我原以为我得写个 C 程序,调几个 ioctl 的,后来网友说有个 sg3_utils 包。甚好,直接拿来用 Python 调,省得研究那几个 ioctl 要怎么写。
#!/usr/bin/env python3
import os
import sys
import struct
import subprocess
import datetime
def set_time(dev):
cmd = ['sg_raw', '-s', '7', dev, 'b0', '00', '00', '00', '00', '00',
'00', '07', '00', '00', '00', '00']
p = subprocess.Popen(cmd, stdin=subprocess.PIPE, stderr=subprocess.PIPE)
dt = datetime.datetime.now()
data = struct.pack('<HBBBBB', dt.year, dt.month, dt.day,
dt.hour, dt.minute, dt.second)
_, stderr = p.communicate(data)
ret = p.wait()
if ret != 0:
raise subprocess.CalledProcessError(ret, cmd, stderr=stderr)
def actionsusbd(dev):
cmd = ['sg_raw', '-r', '11', dev, 'cc', '00', '00', '00', '00', '00',
'00', '0b', '00', '00', '00', '00']
subprocess.run(cmd, check=True, stderr=subprocess.PIPE)
def main():
if len(sys.argv) != 2:
sys.exit('usage: setudisktime DEV')
dev = sys.argv[1]
if not os.access(dev, os.R_OK | os.W_OK):
sys.exit(f'insufficient permission for {dev}')
actionsusbd(dev)
set_time(dev)
if __name__ == '__main__':
main()